During the week, we analysed the dynamic links and changes between online identities and system algorithms. We studied three parts: input, output, and process.
Firstly, in task 1 Input, I started with Instagram to see what I have shared on this social media. I usually share travel photos on this media, including personal selfies, location, time, and mood. Then I went to the privacy centre to view my past activities and private data. Since I have always been more aware of my social media and internet usage activities, I often turn on privacy mode and refuse non-essential cookies.
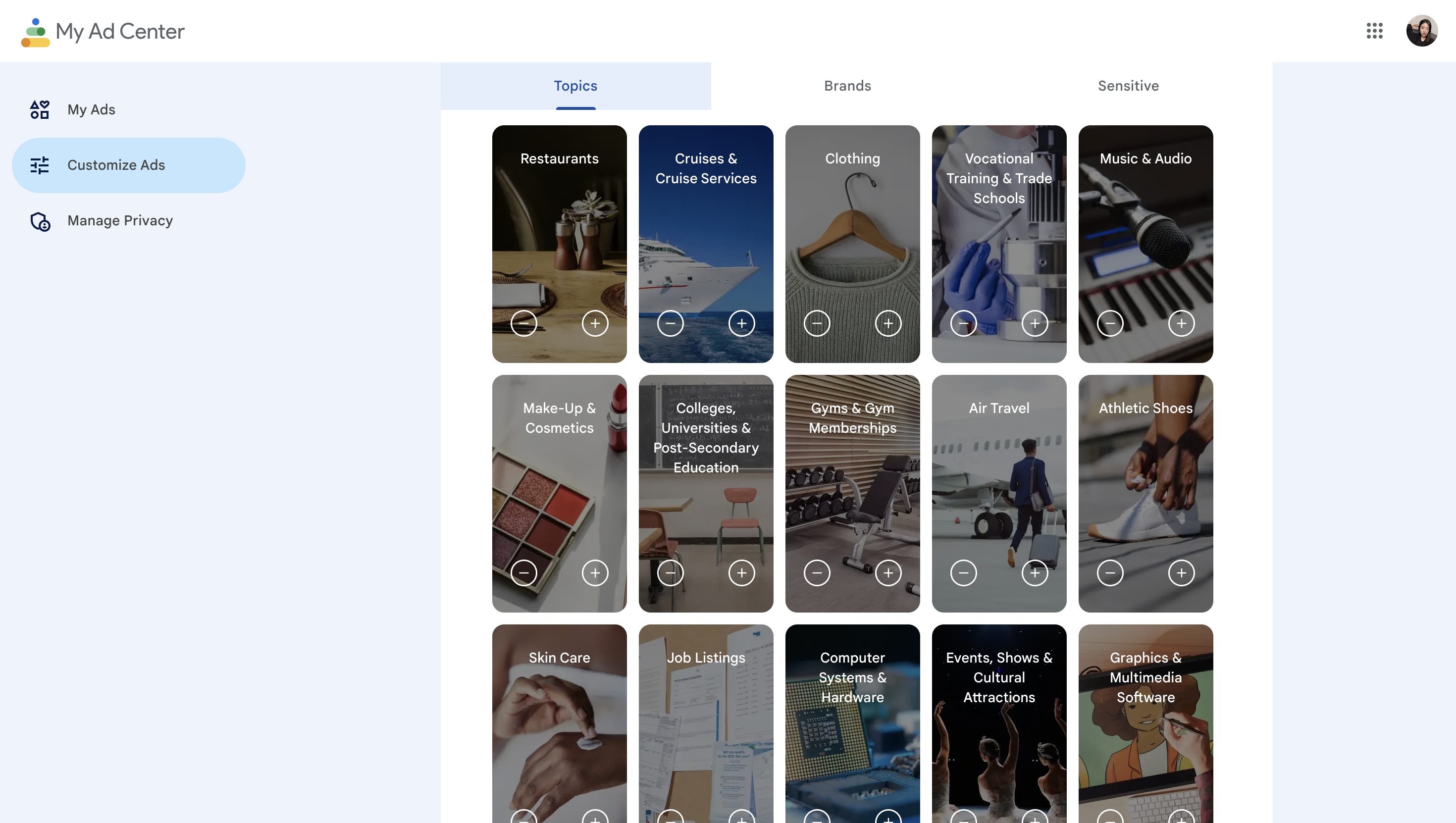
In Task 2 Output, I viewed my Google personality ads. The latest recommended ads are restaurants, cruise ships, and clothes. I think these three appeared because I had searched for relevant information. The platform had analysed them and thought I would be interested in the relevant ads. However, some topics, such as fitness and computer systems, are not my areas of interest. Maybe it was recorded because I had clicked on relevant links before. This kind of advertising campaign prediction is sometimes inaccurate. It only follows my online activities.
I was surprised by the platform's categorisation and analysis of me during the process. This is because I had turned privacy mode on and turned off personalised ad recommendations. In my opinion, my data will not be discovered and analyzed by the algorithm. In order to change the output, I might read more privacy terms to make sure I'm not unknowingly compromising my privacy. In addition, if I want Google to recommend more personal and relevant information to me, I think I need to go into the ad settings and manually select some of my preferences. I think this is similar to the idea mentioned by Cheney-Lippold (2017), which is that our algorithmic identity changes with our media usage. Since we have some fixed preferences, a portion of the algorithms in this fluid identity may be stable and attuned to our personal interests.
Finally, I conducted Sumpter's experimental method. I selected 32 friends from WeChat. The latest 15 posts they posted were categorised according to the 13 categories in the Excel template. This manual crawling process took a long time because we needed to analyze the most suitable category for each post. Sometimes a post often fits two or three categories, but we can only choose one. At the same time, some posts are difficult to classify, such as selfies. I cannot be sure of every meaning and category of different selfies. This analysis task needs two weeks to completed, and other reflection will show in the next week.
Cheney-Lippold, J. 2017. Introduction. We Are Data : Algorithms and the Making of Our Digital Selves. New York: NYU Press, pp. 1-32